| prof. Nunzio Brugaletta | BIt WOrld |
La codifica dei dati alfanumerici è meno problematica di quella dei dati numerici: i caratteri utilizzati in questi dati appartengono ad insiemi finiti. Le problematiche da considerare prevedono la scelta di una quantità di bit tali da poter permettere la rappresentazione dell'insieme dei caratteri e il rispetto dei criteri di ordinamento dei caratteri: qualsiasi sia la codifica adottata, la stringa 'a' deve precedere 'b' o 'ab'.
L'alfabeto inglese è stato il primo codificato sia per questione geografiche (i computer sono nati in nazioni che parlano lingue anglosassoni) che per la sua semplicità (non ci sono, per esempio, le varianti accentate dell'alfabeto italiano).
Considerando la quantità dei caratteri da codificare si arrivò alla conclusione che 7 bit bastavano per codificare tutti i caratteri dell'alfabeto. Con 7 bit si possono produrre 27 = 128 combinazioni diverse: bastano per i caratteri da rappresentare e, in più, si possono utilizzare alcune combinazioni per codificare i codici di controllo che viaggiano dentro un computer.
Inizialmente ogni computer utilizzava la propria codifica che, naturalmente, era diversa da quella di un altro. In questo modo, però, non c'era alcuna possibilità di comunicazione fra computer diversi: era necessario uniformare le codifiche. Al giorno d'oggi la codifica universalmente utilizzata è il codice ASCII (American Standard Code for Information Interchange). Esiste, ancora, un altra codifica utilizzata, però, soltanto nei grossi computer IBM: è la codifica EBCDIC (Extended Binary Coded Decimal Interchange Code).
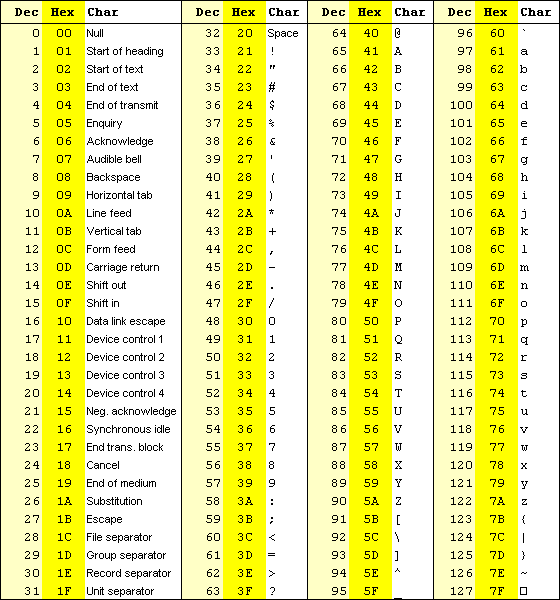
Codifica ASCII
Coerentemente con l'ordinamento alfabetico, per esempio, la lettera 'A' ha un codice immediatamente precedente quello di 'B' (rispettivamente, in decimale, 65 e 66), così che il computer può effettuare un ordinamento che segue le stesse regole utilizzate nell'alfabeto rappresentato.
Per conservare in memoria un singolo carattere in ASCII, teoricamente, basterebbero 7 bit; in realtà ne furono utilizzati 8. L'ottavo bit (quello più significativo) veniva utilizzato come codice di controllo durante la trasmissione del carattere.
Con la diffusione del computer, e l'aumento dell'affidabilità dell'hardware, per implementare i caratteri particolari di alcune lingue, per esempio le lettere accentate in italiano, si pensò di utilizzare l'ottavo bit per espandere il set di caratteri. In questo modo il set di caratteri rappresentabili raddoppia: i codici da 128 a 255, in decimale, furono utilizzati per le localizzazioni. Per poter permettere le comunicazioni fra computer fu stabilito uno standard: ISO 8859 (International Organization for Standardization).
ISO 8859-15

L'ISO 8859 comprende diverse parti che contengono i caratteri specifici di una famiglia di linguaggi: ISO 8859-1, chiamato anche latin-1, è la parte che copre la quasi totalità dei linguaggi dell'Europa dell'Ovest. Successivamente all'introduzione del simbolo dell'euro, fu creato anche ISO 8859-15, ovvero latin-9. La differenza fra ISO 8859-1 e ISO 8859-15 consiste, appunto, nella presenza, nel secondo, del simbolo €.
Il sistema ad 8 bit e l'uso del semplice (senza lettere accentate) alfabeto inglese ha permesso la diffusione di semplici tecnologie di comunicazione. Tuttavia anche con le estensioni ISO, non si è in grado di includere tutte le lingue del mondo: obiettivo perseguito per una comunicazione globale. Inoltre parecchie lingue utilizzano caratteri composti: per esempio, in italiano, una lettera accentata si ottiene come sovrapposizione fra la lettera e l'apostrofo.
Unicode o ISO 10646, standard in costruzione, si propone di stabilire un insieme di regole per rappresentare tutti i possibili caratteri. La rappresentazione nella memoria di un computer prevede una lunghezza variabile in ragione delle esigenze. La realizzazione pratica di questo tipo di codifica comporta l'utilizzo di uno o più byte a seconda del carattere da rappresentare.
La transizione verso l'uso della codifica dell'insieme dei caratteri universali è la codifica UTF-8 (Unicode Transformation Format). Questa codifica permette la rappresentazione, per mezzo dell'uso di più unità di 8 bit, di lettere non presenti nell'alfabeto inglese. I codici corrispondenti al codice ASCII (bit più significativo 0) vengono rappresentati con un solo byte e seguono la solita codifica. Gli altri caratteri, per esempio quelli contenuti nell'ISO 8859-15, sono codificati in più byte: il primo byte (che ha il bit più significativo 1, per distinguerlo dalla codifica a un solo byte), conserva il numero di byte della rappresentazione; nei successivi byte è codificato il carattere.
| http://ennebi.solira.org | ennebi@solira.org |